让不懂建站的用户快速建站,让会建站的提高建站效率!

当地时候7月29日,苹果在官网的一篇论文中涌现,其检修模子接纳了谷歌研发的第四代AI ASIC芯片TPUv4和更新一代的芯片TPUv5。
早在本年6月的民众树立者大会(WWDC)时期,媒体一经在苹果公布的技能文献细节中发现,谷歌成为苹果在AI领域发力的另一位赢家。苹果的工程师在构建基础模子时阁下了公司自研的框架软件及多种硬件,包括仅在谷歌云上可用的张量管束单位(TPU)。只不外,苹果未涌现,比较英伟达等其他AI硬件供应商,苹果有多依赖谷歌的芯片和软件。
TPU—AI检修的专用芯片TPU(张量管束器)是Google 2016年头度推出的用于机器学习的专用管束器。
该管束器擅长大型矩阵运算,不错更高效地检修模子,芯片内集成的HBM也有助于更大规模的模子检修,此外多个TPU不错组成Pod集群,极地面普及了神经汇集使命负载的驱散。
对比当下市集主流的英伟达GPU居品,其主要有以下特色:
中枢数目上,GPU领有大量的管束中枢,不错同期管束多个任务,而TPU其中枢数目相对较少,但每个中枢齐针对深度学习的使命负载进行了优化。
适用范围上,GPU提供了一定的通用性,不错管束包括图形渲染、科学计较和深度学习等任务,而TPU则专注于深度学习中的张量运算,这使得TPU在特定AI计较任务上可能比GPU更快,但在其他类型的任务上可能不如GPU天真或高效。
应用上,GPU因其通用性和天真性而被庸碌应用于各式计较密集型任务,包括但不限于游戏、电影制作、科学盘算、金融建模和深度学习检修。TPU由于其成心为深度学习优化,络续用于需要高蒙眬量和低延伸的深度学习推理任务,如搜索引擎、推选系统和自动驾驶汽车。
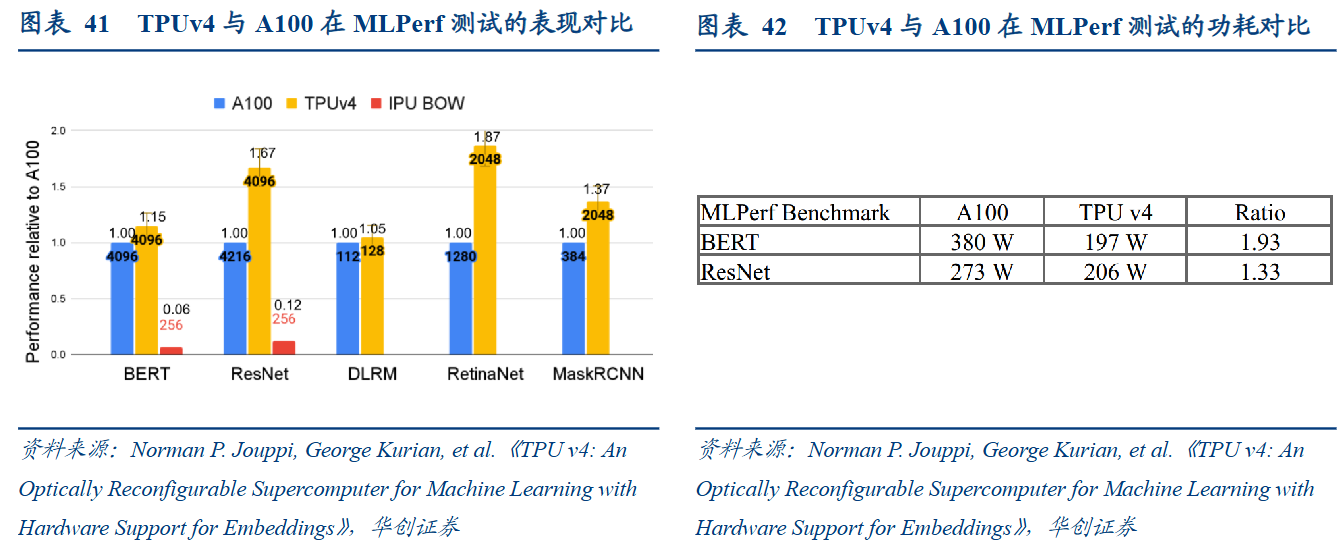
性能上,谷歌曾在一篇论文中暗示,关于规模至极的系统,TPU v4不错提供比英伟达A100强1.7倍的性能,同期在能效上也能提高1.9 倍。
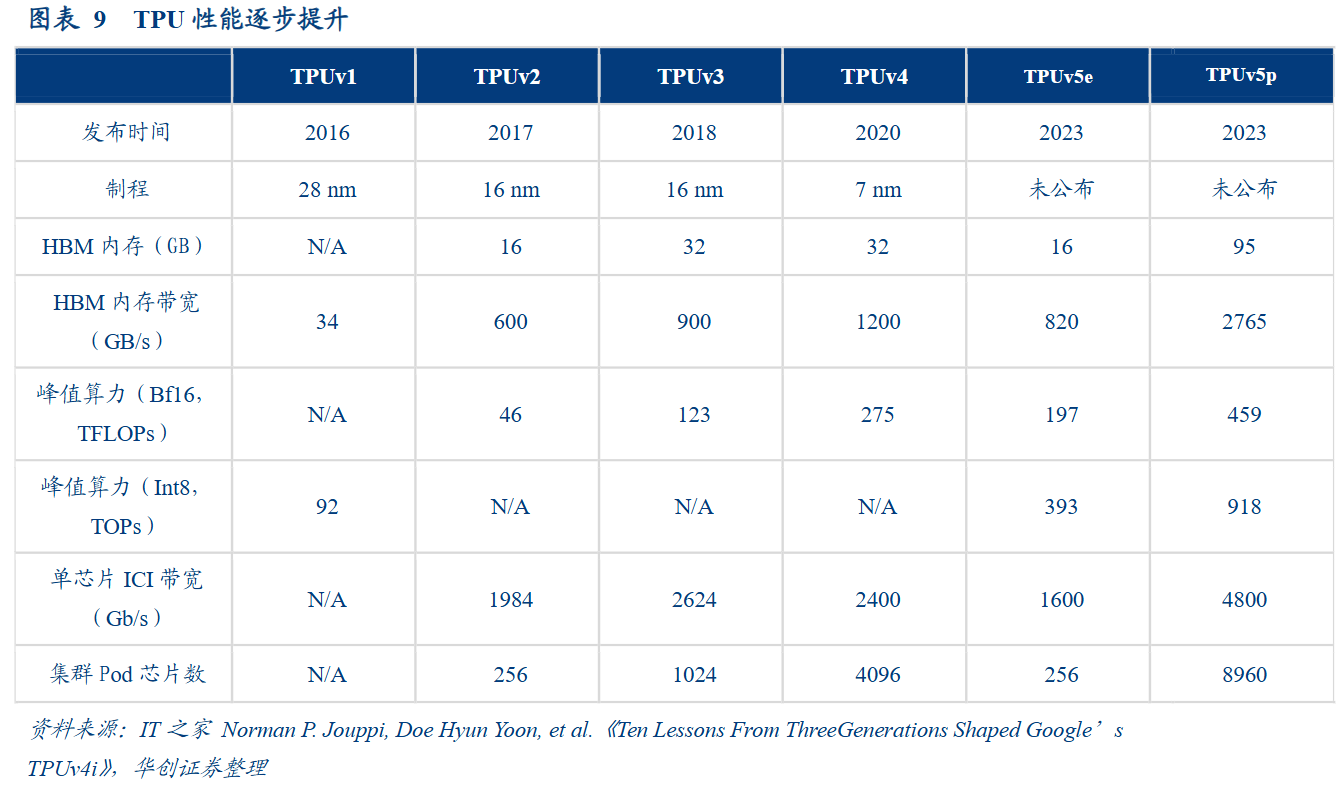
此外据华创证券,2023年Google先后推出TPUv5e及TPUv5p两款芯片。其中TPU v5e,可在相似资本情况下,为大言语模子和生成式AI模子提供相较于TPUv4高达2倍的检修性能和2.5倍的推感性能;TPUv5p则是Google有史以来功能最强大、可扩展性最强、天真性最高的AI芯片,其检修大型LLM模子的速率为TPUv4的2.8倍,较TPUv5e有近50%的普及。刻下,TPU已成为Google大模子检修的主力军。从TPU的使用情况来看,短线炒股当今Google 90%以上的模子检修均在TPU上进行。
另外,据此前Google论文的数据,在搭建TPUv4的集群时,与传统Infiniband交换机有策动比较,OCS(光路交换机)有策动资本更低,功耗更低,部署更快。
OCS是谷歌自研的数据中心光交换机,它通过MEMS系统的阵列组反射结束光信号交换,取代原有光电羼杂交换机体系。
中泰证券指出,谷歌Gemini主要使用TPU v4和TPU v5e大规模检修,且自TPU v4起驱动使用OCS光交换机,其使用基于MEMS的微镜阵列在64个TPU slice之间切换,好像凭阐发质采麇集的数据量,天真选定数据链路和汇集拓展,意味着当采麇集部署更高速率的光模块和交换机时,原有的低速器件不错连续使用,裁汰资本功耗。预测大规模AI芯片组网有望进一步彭胀高速率光模块需求,OCS全光有策动或为光器件带来全新增量。
产业方面,华创证券暗示,基于MEMS的光交换有策动在对数据速率及波长不解锐、低功耗、低延伸等方面齐具备上风,Google选定自研OCS、光模块和光环形器三大主要器件,以组成一个低资本高效益的大规模光交换系统。其中:
1)MEMS反射镜是OCS的中枢组成器件,OCS的翻新性应用,有助于MEMS代工业务的拓展。
2)光模块为适配OCS需求,被再行定制化设想为使用环形器+CWDM4/8的最新一代Bidi OSFP封装。光模块国内企业具有较强竞争力,异日应用技能难度更高,客户粘性有望抓续普及;
3)环形器被翻新性引入光模块内,传输驱散进一步普及。环形器供应链较为熟识,中枢器件法拉第旋转片国产化进度较低,偏振分束器连年国内厂商已具备量产才能;
4)光芯片与电芯片因更高链路预算需求而配套升级,EML及DSP芯片均以外洋供应商为主,国产化进度较低;
5)铜缆与光纤受益Rack表里并吞,带来较大需求。
风险领导及免责条件 市集有风险,投资需严慎。本文不组成个东说念主投资残忍,也未接洽到个别用户独特的投资指标、财务景象或需要。用户应试虑本文中的任何认识、不雅点或论断是否适合其特定景象。据此投资,职守自夸。